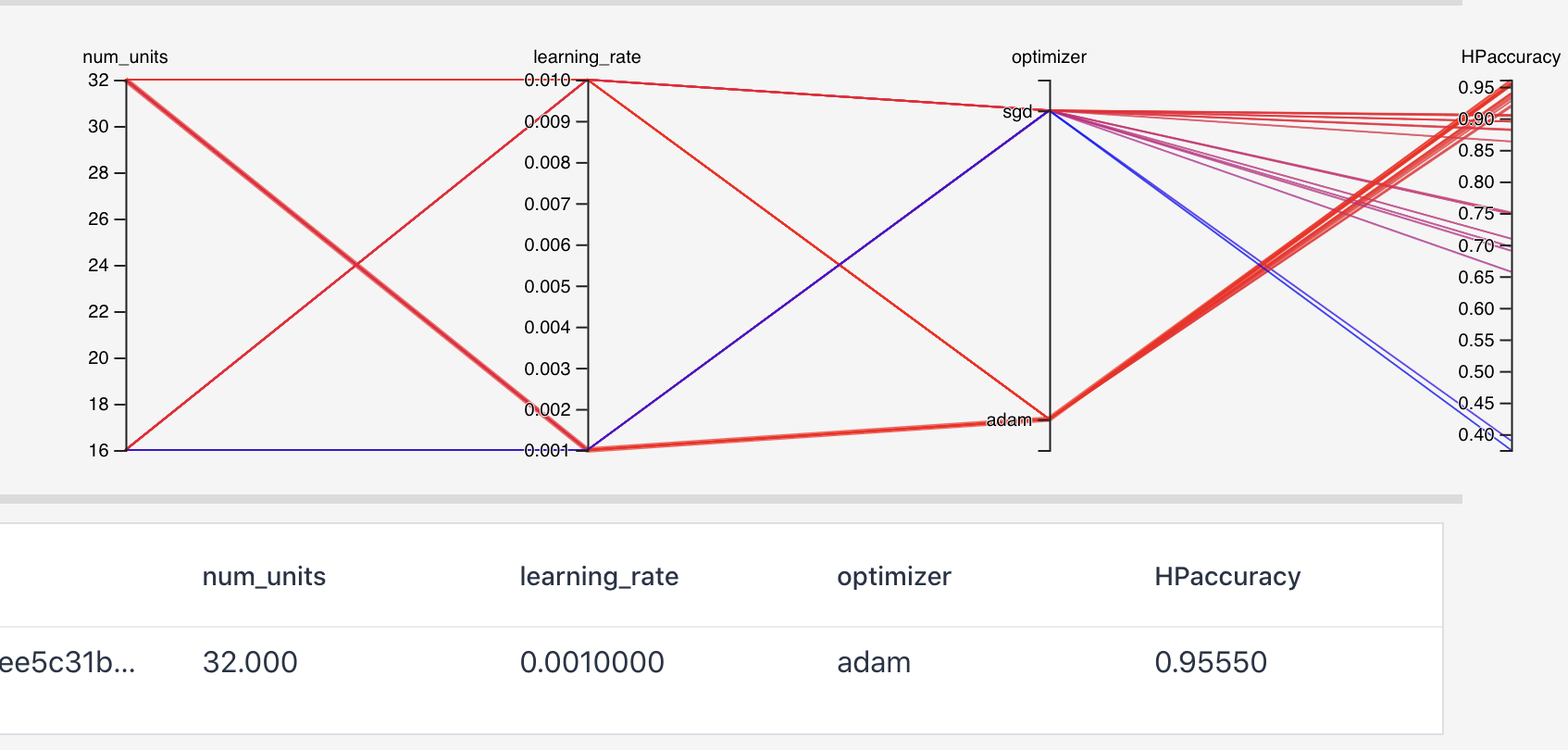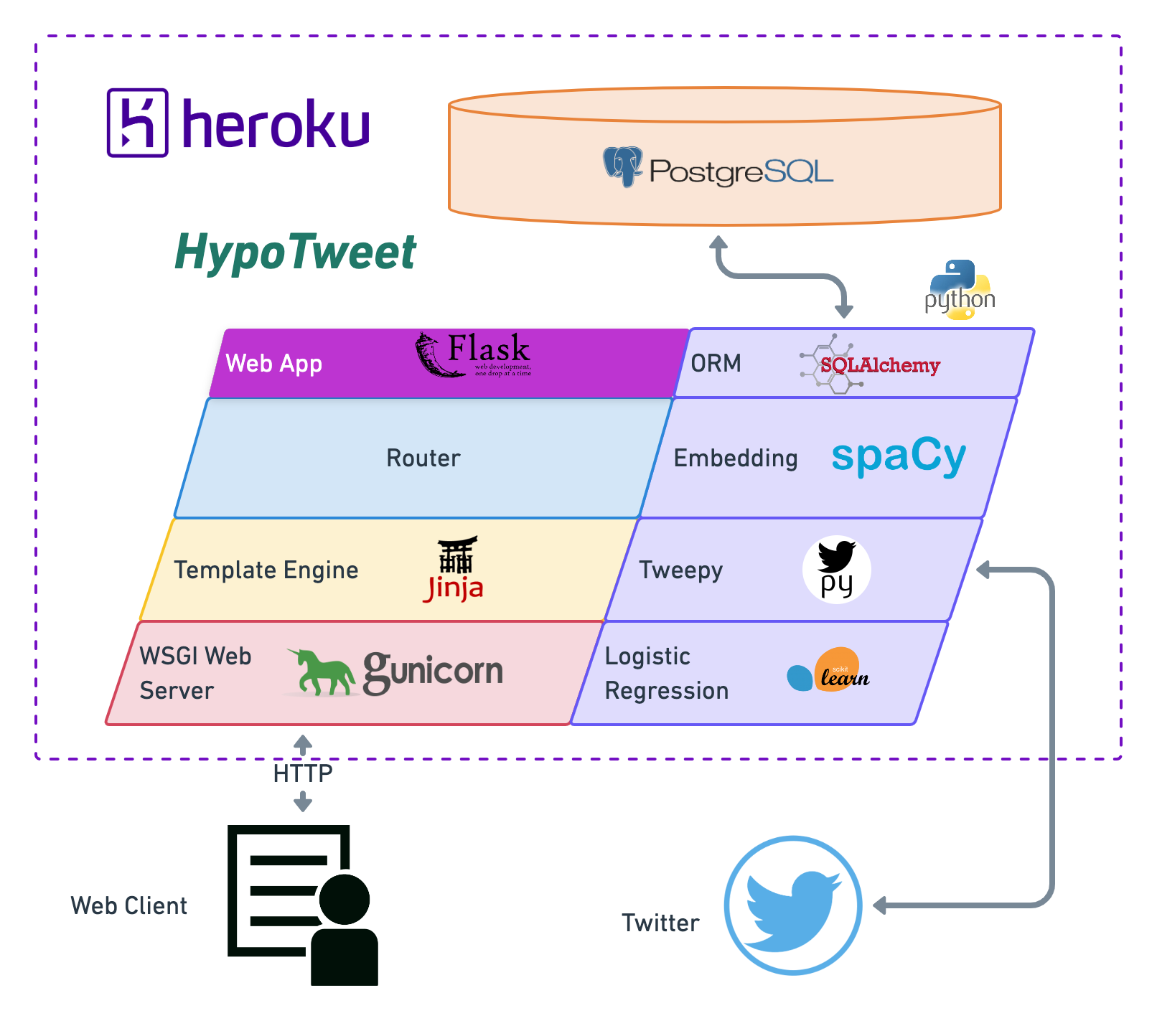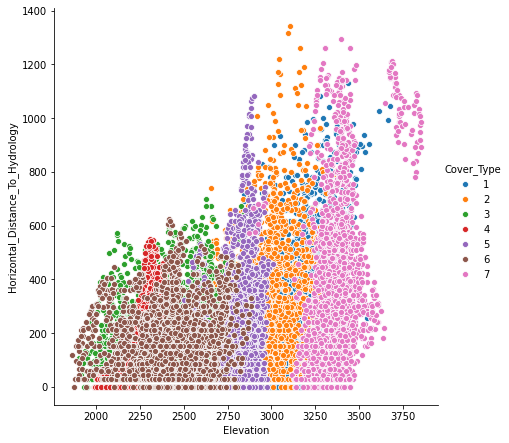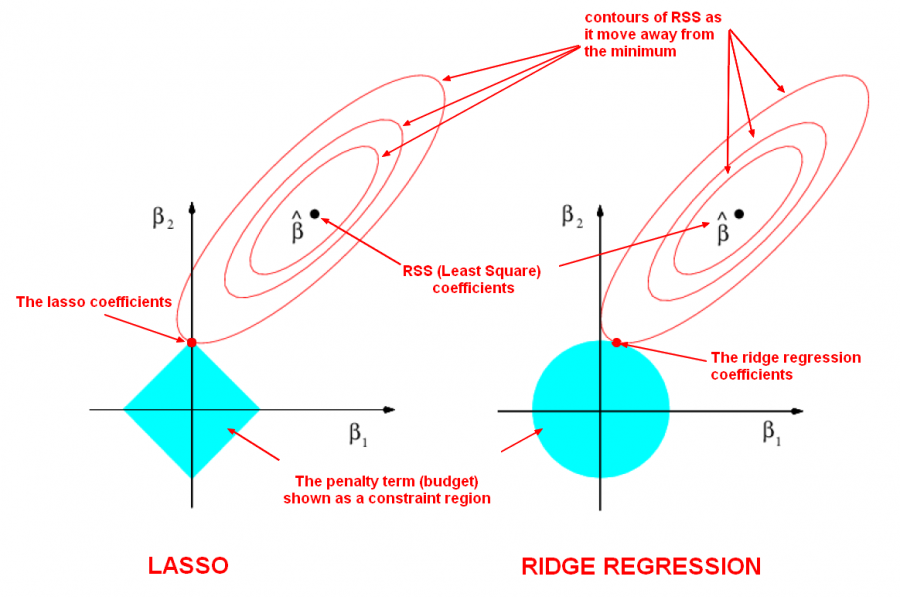
Neural Networks are highly parameterized models and can be easily overfit to the training data. The most salient way to combat this problem is with regularization techniques. A common technique to prevent overfitting is to use EarlyStopping. This strategy will prevent your weights from being updated well past the point of their peak usefulness. We can also combine EarlyStopping, Weight Decay and Dropout, or use Weight Constraint instead of Weight Decay, which accomplishes similar ends.
[Read More]